











AI Meets Accounting
Trullion is an AI-powered accounting platform that automates financial workflows for accounting and audit teams.


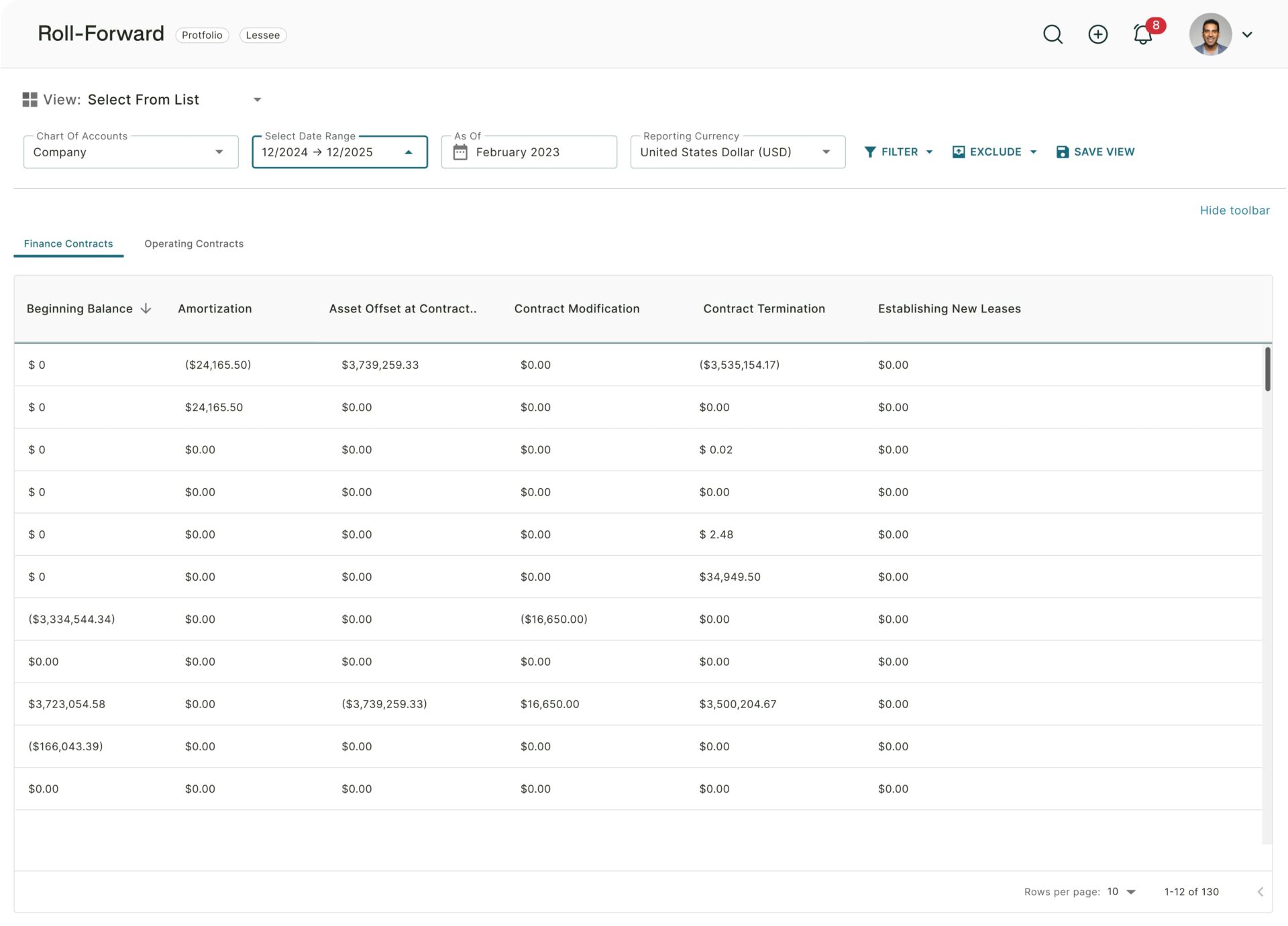
The Trullion Platform
Maximizing impact today, evolving for tomorrow
Trullion combines powerful data automation and GenAI to streamline critical accounting workflows — from ASC 842 lease accounting and revenue recognition to audit readiness. With one unified platform, you can eliminate manual tasks, reduce risk, and stay compliant — effortlessly.


Automate audits from start to finish. Trullion’s cloud-based, AI-powered platform speeds up testing, simplifies reviews, and eliminates silos — so you can deliver accurate results, faster.
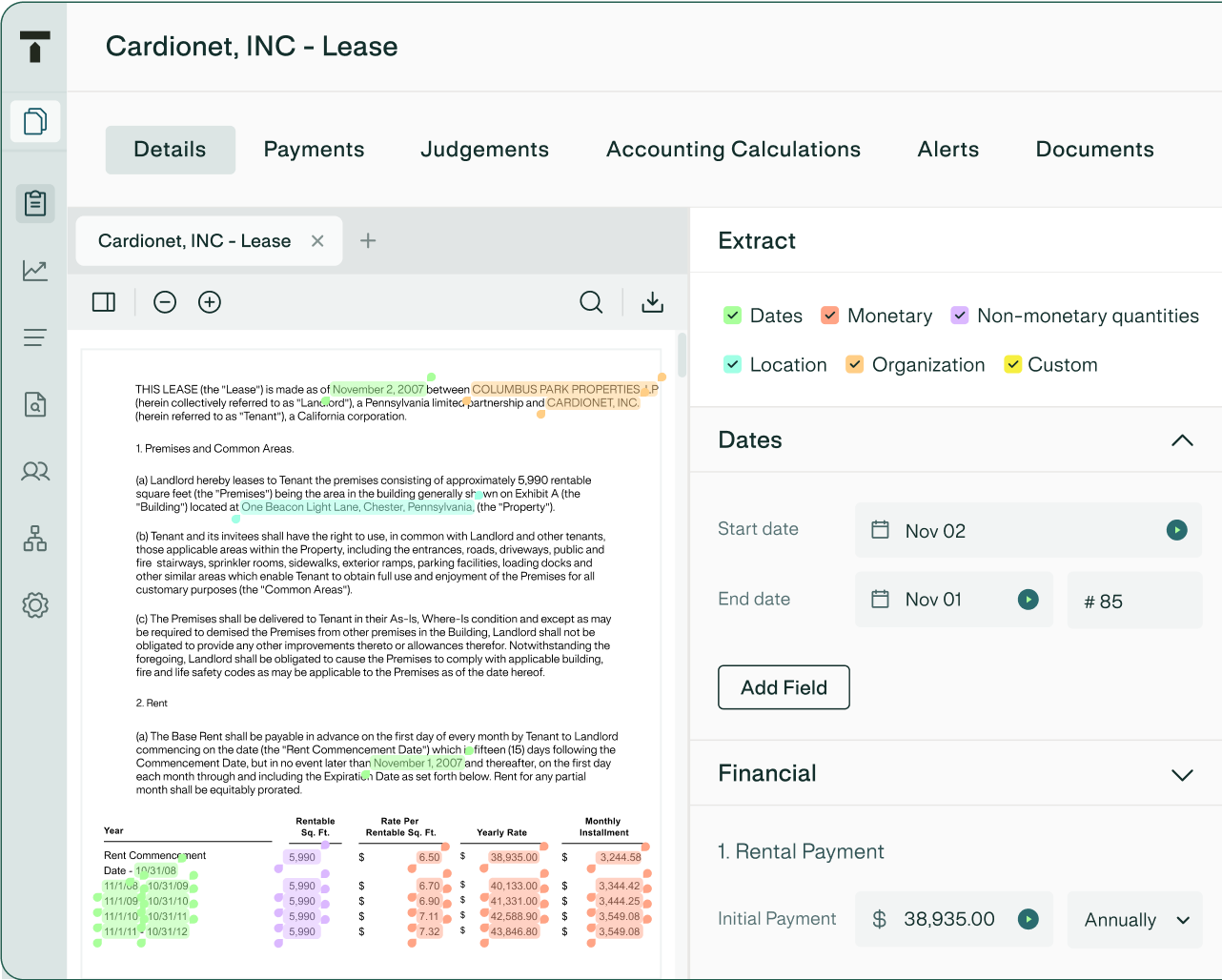
Automate every step of lease accounting — from AI-powered contract extraction to real-time schedules, journal entries, and disclosures. Gain confidence in your compliance and stay audit-ready, always.


Report revenue accurately, set custom rules for your business, and stay in compliance with ASC 606 and IFRS 15.
The future of accounting is agentic AI
Unlock new levels of accuracy and efficiency, with AI designed specifically for accounting. Trulli — your agentic AI assistant — delivers instant answers based on your custom policies, reporting standards, and real-world scenarios.

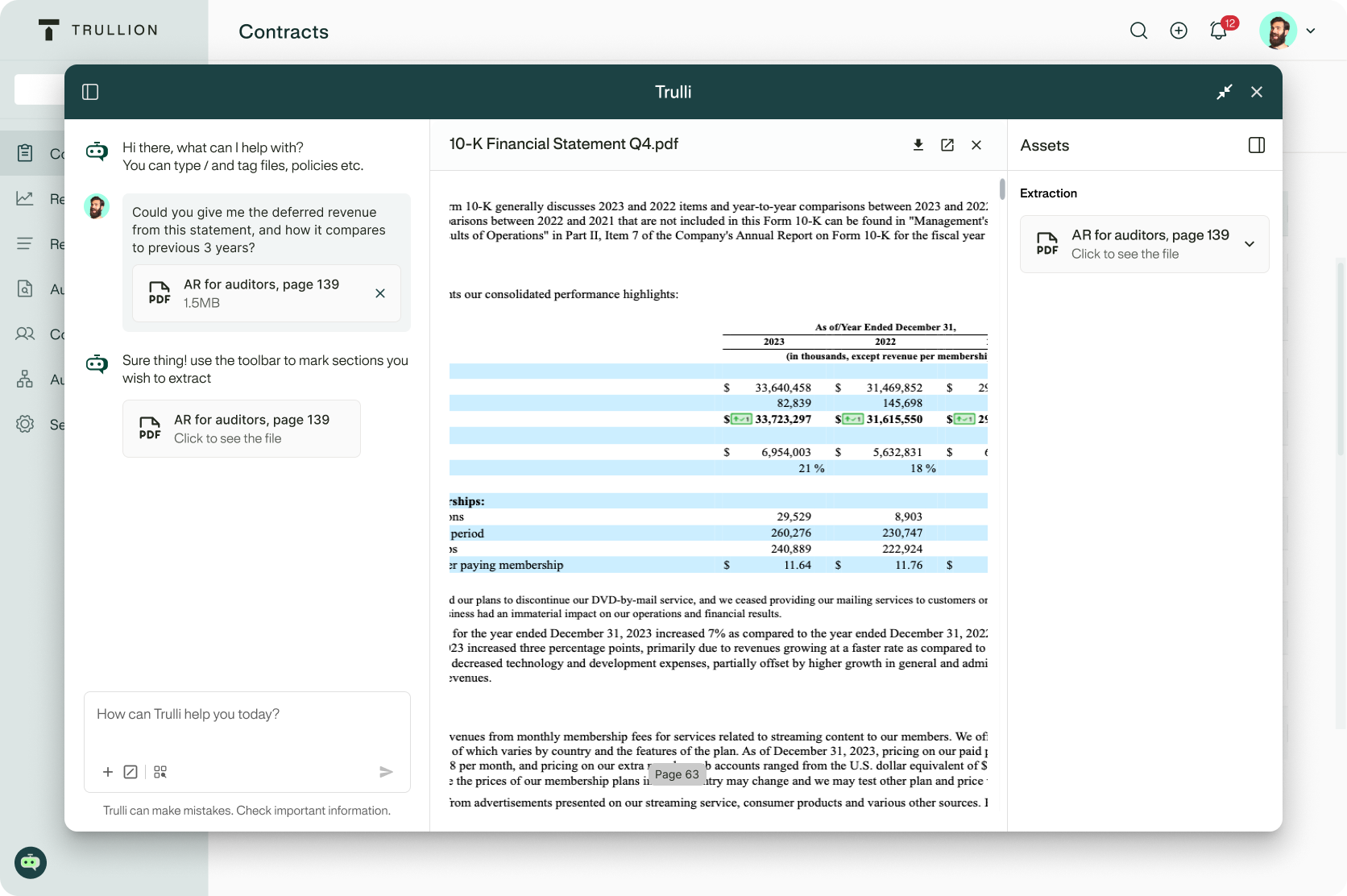
Enterprise-grade AI solution for accounting and finance teams
Whether you're navigating complex audits, managing lease portfolios, or scaling compliance across entities, our AI-powered platform is an extension of your accounting team, adapting to your unique workflows. Here’s how Trullion empowers controllers, auditors, and finance leaders to move faster and smarter:
Audit
Use Trullion to complete audit trail with linked data and formulas. It easier to check calculations and track changes over time.

Controllers
Use Trullion to automate lease accounting tasks, including converting foreign currencies, and tracking asset changes.

CFOs
Use Trullion to access, automate, and reconcile financial liabilities and documents, including leases.

Financial Transformation Teams
Use Trullion to automate workflows, offering quick setups, scalable infrastructure, and ready-to-review reports.
What our customers are saying
